
MLOps now handles the full machine learning lifecycle from training to monitoring. The global market reached about $3.33 billion in 2026. It grows at a 37% CAGR toward $56.6 billion by 2035.
Yet 85% of ML models never reach production. Teams lose time and money on drift, high GPU bills, and post-launch failures.
This roundup covers the updates that matter right now. You get exact case studies, numbers, and one-step fixes. No fluff.
What MLOps looks like in practice today
. It blends data engineering, model training, deployment, and ongoing checks. The focus has shifted to GenAI integration and agentic workflows. Platforms now support LLMs, RAG, and guardrails out of the box.
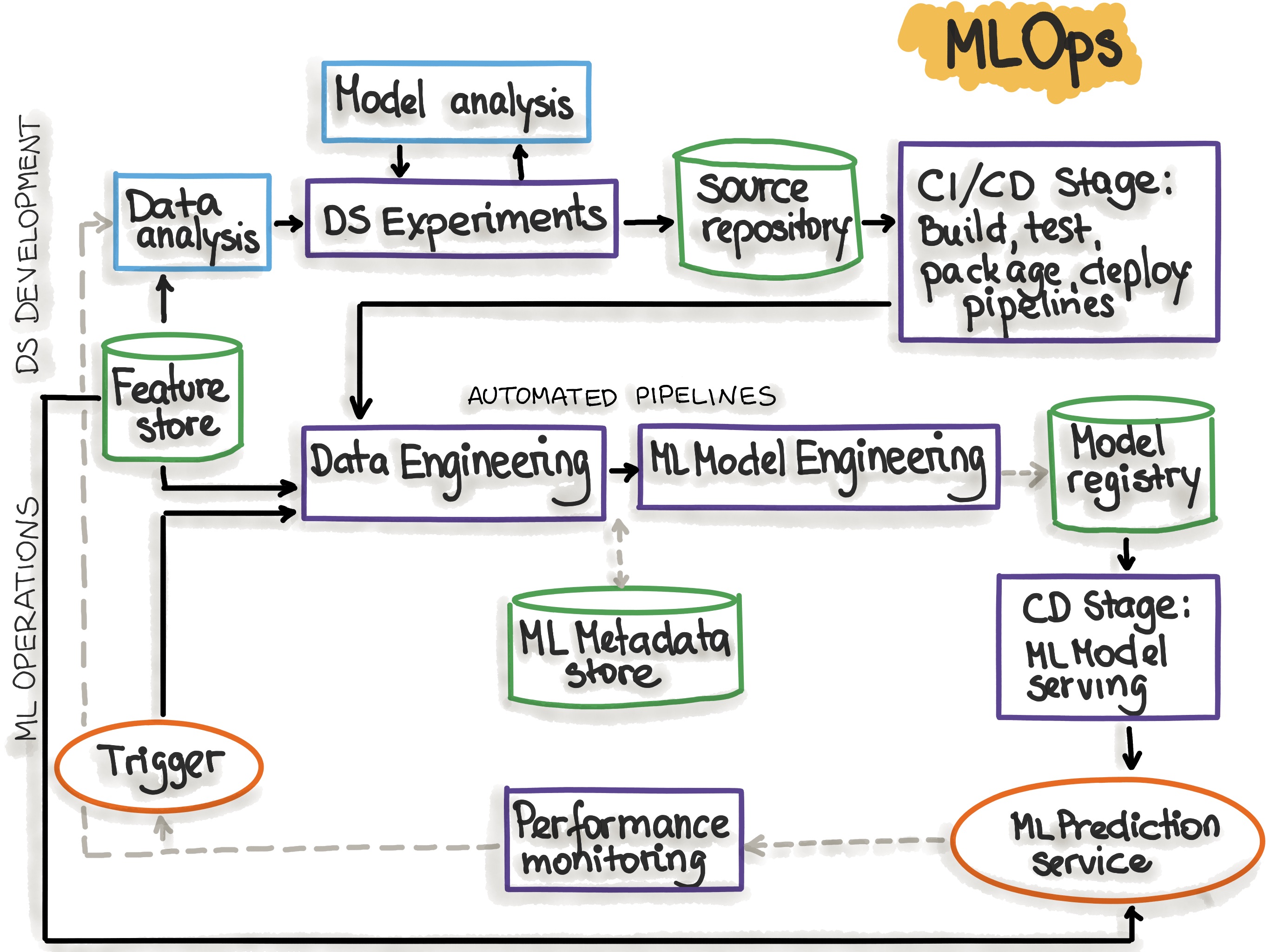
MLOps Principles
1. Scaling ML Infrastructure: GPU Costs and Underutilized Clusters
Single-GPU setups waste resources. Many teams run light models like ASR or TTS at 0-10% utilization.
NVIDIA’s latest guidance shows how to consolidate workloads on Kubernetes. Use Multi-Instance GPU (MIG) partitioning or time-slicing. One test with a voice AI pipeline delivered 35% higher throughput under heavy load. Latency stayed under control.
The fix frees entire GPUs for heavy LLM training. You monitor with Prometheus and the NVIDIA GPU Operator.
Result: lower cloud bills and denser clusters without rewriting code.
2. GenAI and LLM Integration in Production Platforms
PayPal extended its Cosmos.AI platform in late 2025. It now supports vendor LLMs, open-source models, and self-tuned versions.
Features include retrieval-augmented generation (RAG), semantic caching, prompt orchestration, and AI app hosting. The goal was simple: stop LLM features from breaking after launch.
Other teams follow similar paths with Cloudflare’s MLOps best practices. They emphasize prompt management and monitoring to catch drift early.
The payoff shows up in reliable GenAI features that stay stable at scale.
3. Evaluations, Guardrails, and Post-Launch Reliability
Evaluation remains the top pain point. The MLOps World 2026 steering committee survey named evals and testing as the biggest constraint.
Post-launch risks appear fast. Simple LLM features turn complex once live. Retrieval at scale breaks even when demos work perfectly.
MLOps World sessions highlight guardrails, thread-level metrics for agents, and monitoring that catches real failures. One free webinar covers “The Real AI Risk Shows Up After Launch.” Another tackles “LLM Evals & Guardrails In Production.”
Teams now build evals into pipelines. They set thresholds, alerts, and automatic retraining triggers. This cuts silent failures and builds trust with stakeholders.
4. 2026 MLOps Platform Leaders: What Actually Delivered Results
Databricks Mosaic AI tops the latest rankings. Revenue hit $5.4 billion by February 2026. It treats models, data, and agents as one system on a Lakehouse. MLflow 3.x adds high-fidelity traces for retrieval-to-tool workflows.
AWS SageMaker ranks second with $128.7 billion in related revenue. It shines in shadow testing and Bedrock integration.
Microsoft Azure ML follows with strong governance and Prompt Flow for LLMs. Google Vertex AI offers 200+ foundation models and seamless BigQuery ties.
Lower in the list: ClearML for cloud-agnostic flexibility, H2O.ai for AutoML and drift monitoring, Weights & Biases for experiment tracking, and DataRobot for GenAI-specific embedding drift detection.
Each platform solves a different slice—tool sprawl, governance, or multi-cloud needs. Pick based on your stack and risk tolerance.

Streamline AI Infrastructure with NVIDIA Run:ai on Microsoft Azure | NVIDIA Technical Blog
5. Funding and Cost-Cutting Innovations
VESSL AI raised $12 million in Series A. Its platform cuts GPU costs by up to 80% through multi-cloud spot instances and hybrid infrastructure. Smart pausing stops idle resources automatically. Over 50 enterprise customers already use it.
This directly attacks the 80%+ waste many teams see on underutilized GPUs. The ROI formula is straightforward: audit idle time, switch to spot where safe, and monitor with the built-in dashboard.
6. Community and Events Driving Progress
MLOps World | GenAI Summit keeps delivering practitioner sessions. The 2025 event featured case studies from Toyota, Nylas, and others on ROI from pilots to profit. Free stack sessions cover agents & ops plus LLM evals.
The MLOps Community Slack and weekly newsletter share real pipelines. InfoQ and NVIDIA blogs add case studies from Uber, Cloudflare, and production voice AI.
These sources cut isolation. You see what worked for similar teams and skip common mistakes.
30-Day MLOps Improvement Roadmap
Week 1: Run a quick GPU audit and test one consolidation recipe from NVIDIA, Week 2: Add basic evals and guardrails to your top LLM feature, Week 3: Compare two platforms from the ranking against your current stack, Week 4: Implement one cost-cut from VESSL-style spot usage or pausing.
Track metrics weekly: model uptime, cost per run, and eval coverage. Templates for dashboards and checklists come free from the community sessions.
Future Outlook
Agent ops and embedding drift will dominate 2027 planning. Regulatory governance grows stricter in finance and healthcare. Start with traceable lineages and responsible AI dashboards now.
Ignore post-launch monitoring and you risk silent failures. Build evals early and you ship faster with fewer surprises.
FAQs
How do I choose between Databricks and AWS SageMaker in 2026? Look at your data volume and governance needs. Databricks wins for unified Lakehouse work. SageMaker fits heavy AWS users who value shadow testing.
What’s the fastest fix for post-launch LLM failures? Add semantic caching, prompt versioning, and daily eval runs. Monitor retrieval quality at scale first.
Which free tools from recent news can I try this month? Join MLOps World free webinars or grab ZenML/TrueFoundry trial offers listed in their stack drops.
Conclusion
These 2026 updates turn common MLOps headaches into solved problems. GPU costs drop. Platforms mature for GenAI. Evals and guardrails move from nice-to-have to must-have.
Start with one change this week. Your next model deployment will thank you.
Subscribe for the next monthly roundup. Drop your biggest production pain in the comments—I read every one and shape future deep dives around them.






[…] Execution matters more than planning. […]