
Machine visual perception enables computers to process images and videos, extract meaningful information, and make decisions. It powers self-driving cars, medical diagnostics, and quality control in factories.
The global AI in computer vision market stood at around USD 23.42 billion in 2025. It is projected to reach USD 63.48 billion by 2030, growing at a CAGR of 22.1%.
Modern systems achieve over 97% top-5 accuracy on ImageNet classification tasks. This surpasses average human performance of roughly 95%.
Discover More : Computer Vision Ethics & Bias Mitigation Guide
Core Elements of Machine Visual Perception
The process starts with image acquisition through cameras or sensors. Raw pixel data then moves through preprocessing steps that handle noise, lighting variations, and normalization.
Low-level features come next. These include edges, corners, and textures. Early methods used techniques like SIFT and HOG. Today, convolutional neural networks extract these automatically in initial layers.
Mid-level processing groups features into object proposals and performs semantic segmentation. This labels every pixel in an image.
High-level stages deliver object recognition, scene understanding, and 3D reconstruction. Fusion with other data types, such as text or depth information, creates richer interpretations in current multimodal systems.
Human Visual Perception vs. Machine Visual Perception
Human vision relies on the retina and visual cortex. It builds hierarchical features and handles context naturally. Machines rely on statistical patterns learned from massive datasets.
Humans excel at robustness to occlusion, unusual viewpoints, and noisy conditions. Machines scale well but often fail on domain shifts or adversarial examples without specific training.
On standard benchmarks, top AI models now outperform humans in narrow classification tasks. Real-world scenarios still expose gaps in generalization and common-sense reasoning.
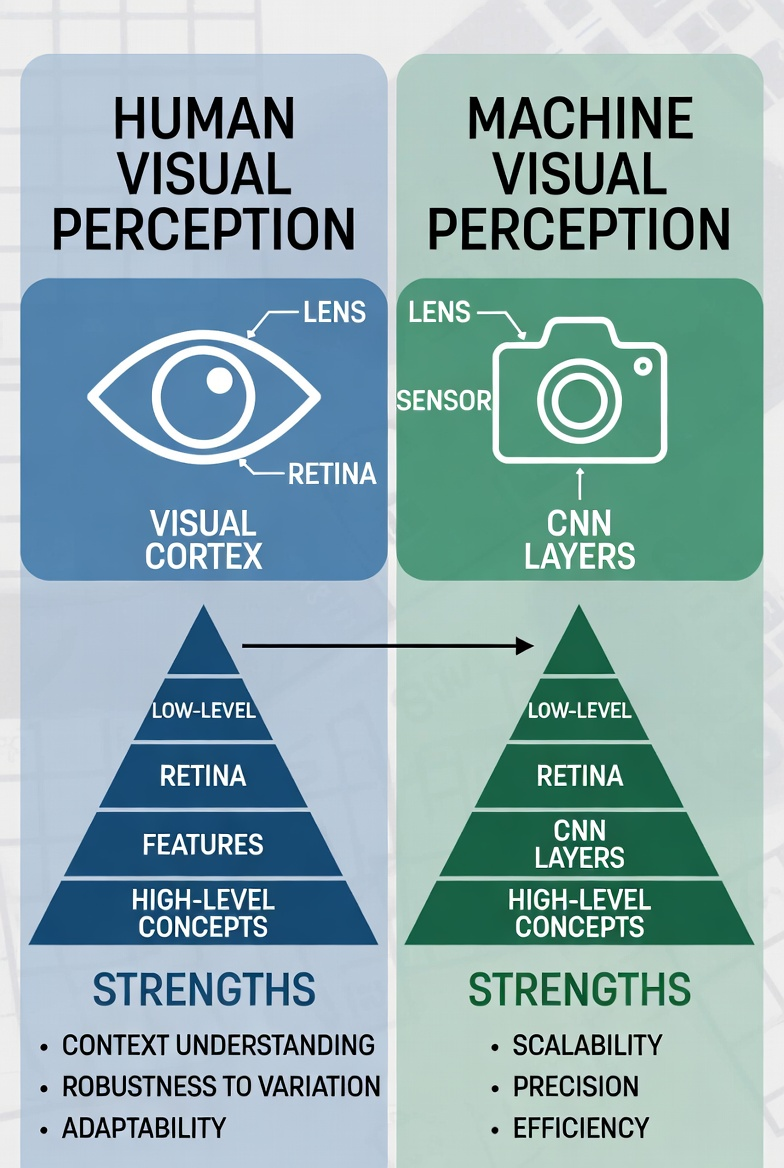
This comparison highlights practical trade-offs engineers face when building systems.
The End-to-End Pipeline
Image acquisition captures data from sensors. Preprocessing corrects distortions and enhances contrast for better downstream results.
Convolution operations form the backbone of feature extraction. A basic convolution can be expressed as:
(f∗g)(x,y)=∑i∑jf(i,j)⋅g(x−i,y−j)
This slides filters across the image to detect patterns.
Object detection models like the YOLO series locate and classify multiple items in one pass. Segmentation models such as U-Net or Segment Anything provide pixel-precise masks.
3D reconstruction techniques, including Neural Radiance Fields (NeRF) and Gaussian Splatting, turn 2D views into navigable scenes. These steps connect raw input to actionable output.
Key Technologies Powering Progress
Classical methods used rule-based edge detectors and statistical models like SVMs. Deep learning shifted the field with CNN architectures such as ResNet and EfficientNet.
Vision Transformers (ViT) process images as sequences of patches. They capture long-range dependencies better than traditional convolutions in many cases.
Advanced approaches now include self-supervised learning. This reduces dependence on labeled data. Diffusion models support generative tasks tied to perception.
Frameworks like PyTorch and OpenCV, along with Hugging Face, make experimentation accessible. For example, fine-tuning a YOLO model on custom data takes hours instead of months.
Major Challenges and Practical Solutions
Real-world lighting, weather, and domain shifts cause performance drops. Domain adaptation and sim-to-real transfer help close these gaps.
Edge devices demand efficiency. Model quantization, pruning, and lightweight architectures address memory and speed constraints while maintaining accuracy.
Interpretability remains an issue. Attention maps and explainable AI techniques reveal why a model made a specific decision.
Data bias and scarcity affect outcomes. Synthetic data generation and self-supervised pretraining mitigate these problems effectively.
Real-World Applications
Autonomous vehicles combine visual perception with LiDAR for safe navigation. Medical imaging systems detect tumors with high sensitivity, often catching details radiologists might miss under time pressure.
Manufacturing lines use vision for defect detection at speeds impossible for humans. Agriculture drones monitor crop health across large fields. AR/VR experiences rely on accurate scene understanding for realistic overlays.
Future Directions
Multimodal models integrate vision with language and action. This enables more natural human-AI interaction. Neuromorphic hardware promises brain-like energy efficiency.
Researchers focus on robustness benchmarks and embodied AI. Ethical issues around bias, privacy, and accountability require ongoing attention.
Conclusion and Takeaways
Machine visual perception transforms pixels into understanding through layered processing, learning algorithms, and geometric reasoning. Start with open datasets like COCO or ImageNet. Experiment with pre-trained models from Hugging Face. Measure performance on your specific conditions rather than public benchmarks alone.
For deeper reading, check the Computer vision page on Wikipedia.
This foundation equips developers, engineers, and decision-makers to build and evaluate effective systems today. Apply these concepts step-by-step in your projects for measurable results.





