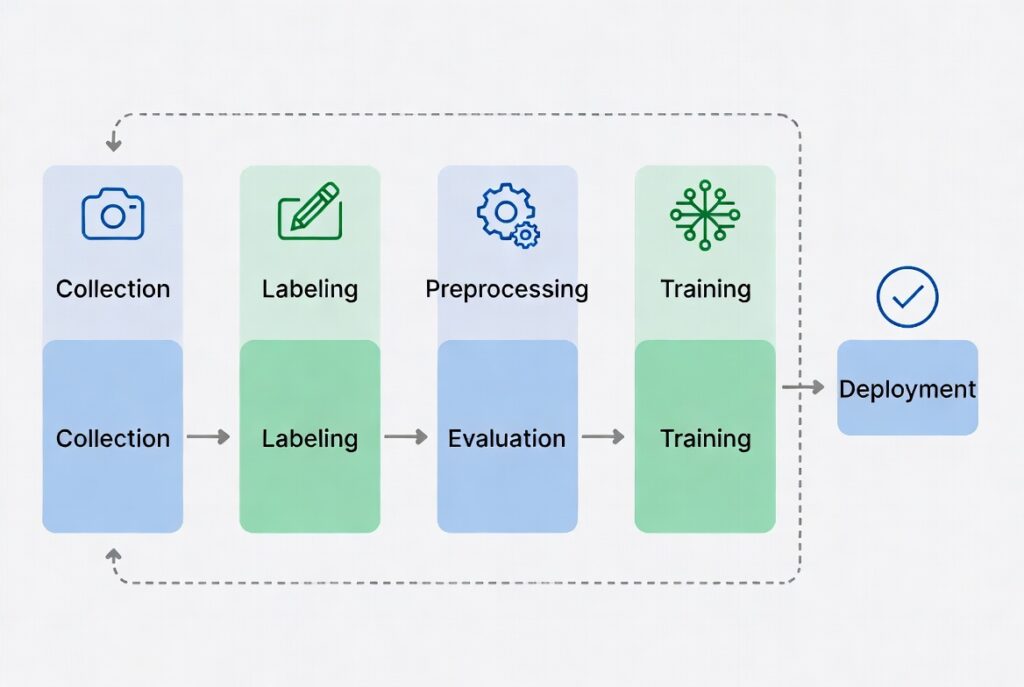
Building a computer vision data pipeline takes 60-80% of total project time in most ML teams. Poor data handling leads to inconsistent models, wasted labeling budgets, and failed deployments. This guide walks you through a practical, end-to-end process that solves these issues directly.
Data collection, labeling, preprocessing, versioning, and monitoring form the core. Active learning can cut labeling costs by 40-60% while maintaining or improving model performance. Versioning tools like DVC prevent dataset chaos. Structured pipelines improve reproducibility and reduce model drift in production.
Start with clear objectives. Map your business problem to a specific CV task—object detection, semantic segmentation, or instance segmentation. Define metrics early: mAP@0.5 for detection, IoU for segmentation, or inference latency for edge devices. Estimate required data volume and diversity upfront.
Define Objectives and Plan Your Pipeline
Skip vague goals. List exact requirements: image resolution, lighting conditions, occlusion levels, and rare edge cases. Create a data diversity matrix covering angles, backgrounds, and object variations.
Decide on architecture next. Batch processing works for most offline systems. Streaming fits real-time video. Choose cloud (AWS S3 + SageMaker), on-prem, or hybrid based on compliance needs like GDPR for sensitive images.
Budget for labeling and storage. Factor in iteration cycles—most successful projects run 3-5 data collection rounds.
Next step: smart collection avoids common waste.
Data Collection Strategies
Begin small. Collect initial sets of 20,000–50,000 images, then iterate based on model feedback. This tiered approach prevents over-collection of useless data.
Mix sources effectively:
- Public datasets like COCO or Open Images for baseline training.
- Domain-specific real data from cameras, drones, or sensors.
- Synthetic data via BlenderProc or CARLA for rare scenarios like night-time defects or extreme weather.
Match your collection to final inference hardware. A model trained only on high-res web images fails on low-quality factory cameras. Use tools like Lightly for on-device smart filtering to select diverse samples automatically.
Once collected, labeling becomes the next bottleneck.
Data Labeling and Quality Assurance
Labeling often costs the most. Hybrid approaches work best: combine in-house experts for complex cases with outsourced platforms for scale.
Recommended tools include Roboflow, CVAT, and Label Studio. These support bounding boxes, polygons, and keypoints.
Implement quality gates. Run double reviews on 10-20% of samples. Use embedding visualizations to spot duplicates or outliers quickly.
Active learning delivers big gains here. Train a quick initial model, then label only uncertain or diverse samples. This loop reduces total labeling needs significantly without losing accuracy.
Track metadata like collection date, source, and annotator for later auditing.
Clean and organized data prevents downstream headaches.
Storage, Versioning, and Data Management
Store raw images in scalable buckets like AWS S3 or Google Cloud Storage. Keep annotations and metadata separate for easy updates.
Use DVC (Data Version Control) or similar for full reproducibility. Version both images and labels so you can roll back experiments reliably.
Build a simple data catalog. It should show dataset versions, sources, and changes over time. This practice alone saves hours during debugging or audits.
With solid storage in place, preprocessing becomes straightforward.
Preprocessing, Cleaning, and Augmentation
Start cleaning immediately. Remove corrupt files, fix orientations, and eliminate near-duplicates using perceptual hashing.
Build reproducible pipelines with PyTorch’s torchvision or TensorFlow’s tf.data. Normalize pixel values consistently. Resize images to your model’s expected input size.
Apply targeted augmentations. Geometric transforms (rotate, flip, crop) plus domain-specific ones (brightness jitter, weather effects) help generalization. Avoid random heavy augmentation that creates unrealistic samples.
Automate the entire flow. This ensures every experiment uses identical preprocessing steps.
Proper splits now determine how well your model generalizes.
Data Splitting, Curation, and Feature Engineering
Use stratified splits: roughly 70% train, 15% validation, 15% test. Account for domain shifts—don’t mix factory and outdoor images randomly across sets.
Leverage embeddings for curation. Tools can rank samples by diversity and representativeness, helping you keep high-value data only.
Address imbalance with weighted sampling or class-specific augmentations rather than synthetic oversampling alone.
Training integrates everything you built so far.
Model Training and Experimentation
Choose PyTorch or TensorFlow based on team familiarity. Start with fine-tuning pre-trained backbones like ResNet, EfficientNet, or modern vision transformers.
Connect your data loaders directly to the pipeline. Track experiments with Weights & Biases or MLflow to compare versions easily.
Monitor training for overfitting using validation metrics. Run hyperparameter searches on a small scale first.
Evaluation reveals real weaknesses.
Evaluation, Validation, and Iteration
Look beyond overall accuracy. Use confusion matrices, per-class metrics, and slice-based analysis (performance by lighting or object size).
Test on true edge cases collected separately. Human review on failure modes feeds the next data collection round.
Close the loop: insights from evaluation improve collection, labeling, and augmentation in the next iteration.
Production readiness separates prototypes from reliable systems.
Deployment, Monitoring, and Maintenance
Export models to ONNX or TensorRT for faster inference. Deploy via APIs, edge devices, or platforms like Roboflow.
Set up monitoring for data drift and performance degradation. Trigger retraining automatically when metrics drop.
Implement CI/CD for both data pipeline and model updates. This keeps systems stable as new data arrives.
Recommended tools overview
Tools and Tech Stack Recommendations
Lightly excels at data curation and active learning. Roboflow offers end-to-end workflows from upload to deployment. Encord and DVC handle complex pipelines and versioning.
Compare options based on team size and budget. Open-source stacks give control but need more maintenance. Managed platforms speed up iteration.
Avoid these common issues
Common Pitfalls and Advanced Tips
Many teams ignore data drift after deployment. Others skip versioning and lose track of what trained which model.
Use hybrid real + synthetic data for rare classes. Integrate MLOps practices early. For video pipelines, add temporal consistency checks.
Stay updated with data-centric AI trends. Foundation models change labeling needs but make quality data even more critical.
Wrapping up the process
Conclusion and Action Plan
A solid computer vision data pipeline combines planning, smart collection, efficient labeling, automation, and continuous monitoring. Follow these steps to reduce costs, improve accuracy, and ship reliable models faster.
Download a starter checklist and basic DVC + PyTorch pipeline template (links in resources section). Begin with a small pilot on one use case. Measure time and cost savings after two iterations.
This approach has helped teams cut labeling expenses while delivering production-grade results. Apply it step by step to your next project.
Further reading: Computer Vision on Wikipedia
This guide focuses on practical solutions that address real production challenges in computer vision projects.






[…] – 25May2026 AI Technology Model Architecture Best Practices for CV Deployments in 2026 AI Technology How to Build a Computer Vision Data Pipeline […]
[…] How to Build Your Computer Vision Data Pipeline Model Architecture Best Practices for CV Deployments […]